Diary of Chanjun 데이터 분석가의 다이어리
데이터 분석가가 Python에서 한번씩 보지만 궁금하지 않았던 것들

학습목적 데이터 분석가로써 가끔 한번씩 혹은 미쳐 몰랐던 파이썬의 기능들의 몇가지를 소개하고, 이해해보도록 한다. 목차 f string decorator underbar/under score Asterisk jupyter magic key F string 분석을 하다보면 확인을 위해서 print한다던지, 혹은 query를 자동화한다던지 또는 어떤 데이터셋을 만들 때도 흔히 쓰이는 ““.format을 많이 사용하게 됩니다. r에서는 paste나 sprintf를 사용하게 됩니다. 파이썬에서는 ~r보다 조금 자유롭고 편한하... Read more 08 Aug 2021 - 11 minute read
AE3. Denoising AE - 노이즈제거 오토인코더란?
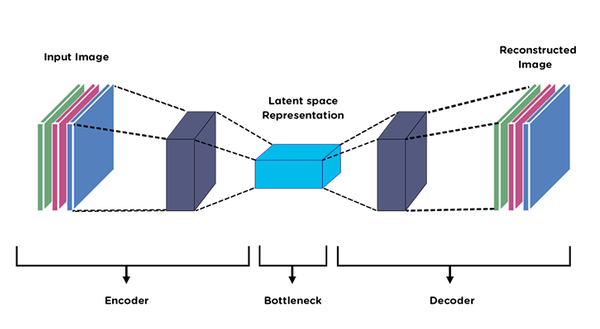
학습목적 이 포스팅에선 오터인코더의 한 사례인 노이즈가 추가된 데이터에서 깨끗한 이미지를 뽑아낼 수 있는 Denoising AutoEncoder에 대해서 알아보겠습니다. Denosing AutoEncoder Denosing AutoEncoder는 이미지 데이터에 노이즈가 있을 때 제거할 수 있도록 학습되는 AutoEncoder 중에 하나입니다. 크게 네트워크 모양이 바뀌지는 않지만 기존 AE와 다르게 X, Y값이 다르다는 점이 있습니다. 왜 노이즈 제거에 AE를 사용할까? AutoEncoder는 차원을 축소시키면서 데이터를 함축적으로 표현하게 되어있습니다. 즉, 핵심적인 데이터만 저장하도록 되어... Read more 27 Jul 2021 - 27 minute read
AE1. Auto Encoder란 무엇일까?
학습목적 이 포스팅에선 GAN을 배우기 전 이미지를 생성하는 오토인코더에 대해서 알아보도록 하겠습니다. 오토인코더란? 오토인코더(Autoencoder)의 기본적인 개념은 저차원(직관적)인 데이터를 고차원(추상적)의 데이터로 표현(representation)하고 다시 저차원의 데이터로 만들어 데이터 생성, 노이즈 제거, 특성 변화 등을 할 수 있도록 만들어주는 기법으로, 오토 인코더라고 불리지만 실제로는 인코더와 디코더가 같이 묶여있는 네트워크입니다. 저차원과 고차원 인코더는 차원 축소라고 표현되나, 잠재공간(Latent Space)가 늘어나며 추상적인 고... Read more 25 Jul 2021 - 14 minute read
Loss function for Regression Model
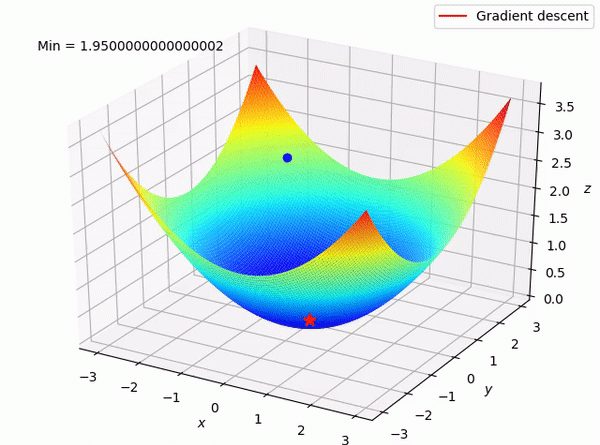
학습목적 이 포스팅에선 머신러닝/딥러닝에 쓰이는 Loss function에 대해서 알아보겠습니다. 1. Objective / Cost / Loss function 만들고자 하는 머신러닝/딥러닝 모델을 만들 때 대체로 Loss function이란 말을 쓰지만 조금의 차이가 있을 수 있으니 위 세개의 말이 어떻게 다른지 알아보겠습니다. 1. Objective Function(목적 함수) 목적함수는 셋 중에 가장 큰 범위로 말 그대로 모델을 만드는 목적을 말합니다. 보통 Loss function은 오차를 최소화하기 위한 것이지만 MLE 같이 최대화하는 경우는 Loss function에는 포함되지 않습니다... Read more 05 Jul 2021 - 14 minute read
시계열 데이터 - LSTM
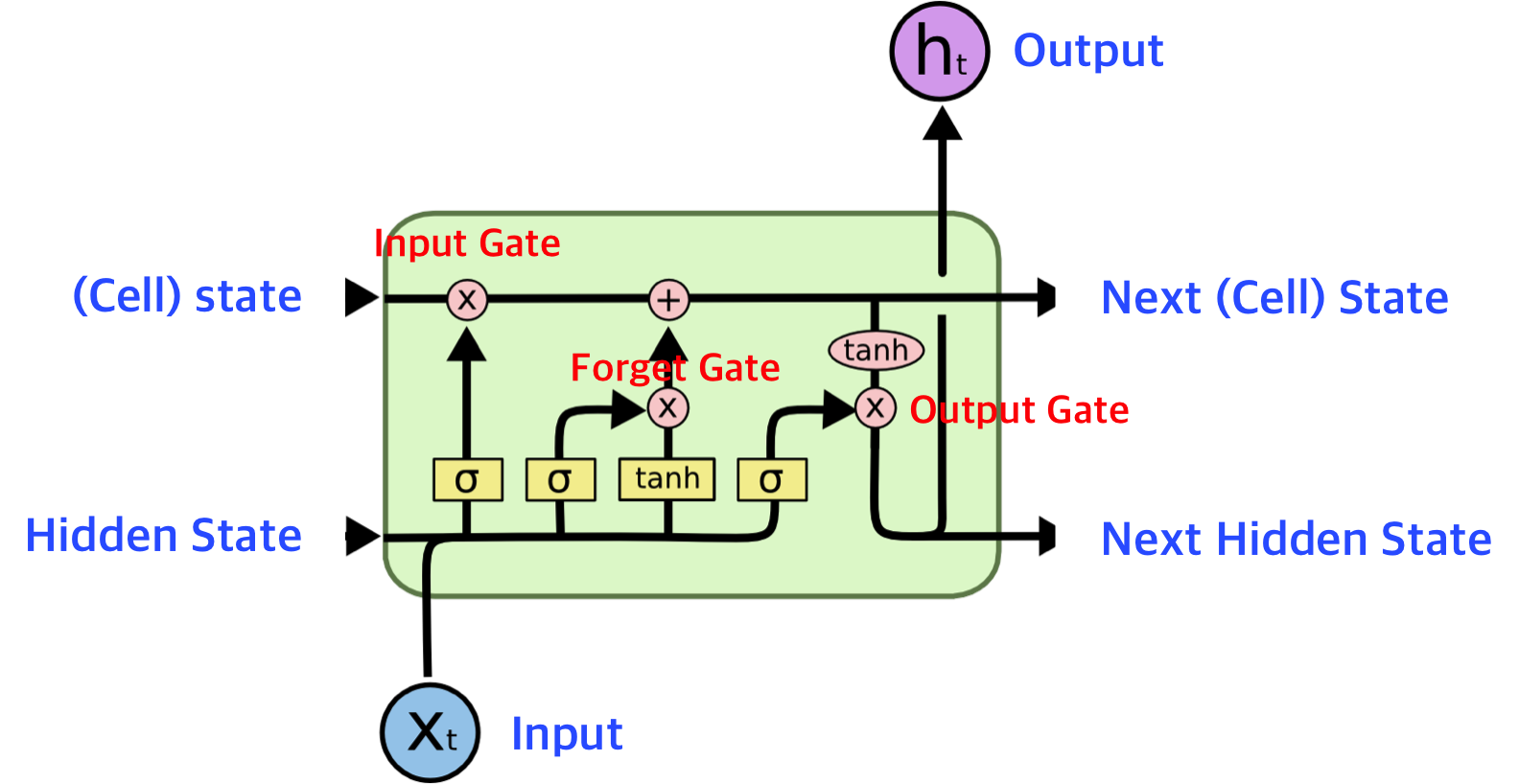
학습목적 이 포스팅에선 시계열 데이터를 다루는 딥러닝 기술인 LSTM을 활용하여 예측을 해보겠습니다. 데이터를 쉽게 만들기 위하여 제공되는 TimeseriesGenerator를 활용하여 데이터셋을 구축을 해보겠습니다. 이 글은 LSTM을 활용하고 다양하게 모델 및 파라미터를 바꾸는 것에 집중되어 있습니다. (LSTM의 원리 등은 나중에 따로 포스팅하도록 하겠습니다.) 또한 데이터 EDA에 대한 글은 따로 포스팅하겠습니다. import os import sys import warnings from tqdm import tqdm import itertools import numpy a... Read more 15 Jun 2021 - 73 minute read
시계열 데이터 - ARIMA
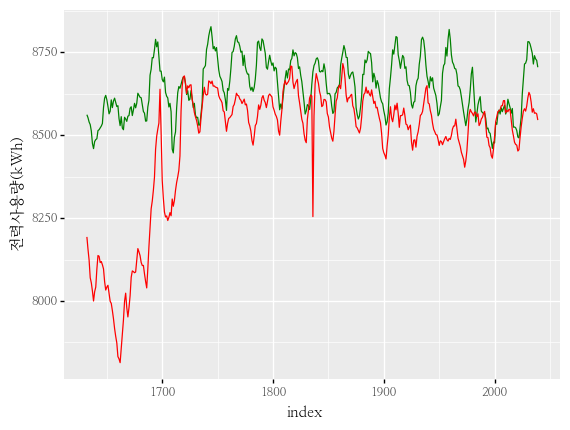
학습목적 시계열 데이터를 다루는 법과 시계열 예측을 하기 위한 여러가지 모델을 사용해보고 특성을 이해한다. 이를 위해서 데이콘에서 진행 중인 대회인 전력사용량 예측 AI 경진대회의 데이터를 사용하고, 베이스라인 코드를 따라하고 또 나만의 코드로 만들어 결과를 제출하여 순위도 확인해볼 것이다. 이 장에서는 ARIMA 모형만 다루고 EDA를 다루지 않습니다. 시계열 데이터란? 일정 시간 간격으로 배치된 데이터 시계열 분석의 목표 이런 시계열이 어떤 법칙에서 생성되는지 기본적인 질문을 이해하는 것 시계열 예측 주어진 시계열을 보고 수학적인 모델을 만들어서 미래에 일어날 것들을 예측하는 것 (X가 시계열 Y가 ... Read more 08 Jun 2021 - 12 minute read
CNN에 관하여
학습목적 이미지 데이터를 처리하고 학습하는 딥러닝 모델 중 CNN을 공부하고 오픈 이미지 데이터를 가지고 한 스텝 한 스텝 따라가본다. CNN이란? Convolutional Neural Network의 약자로 주로 이미지나 영상 데이터를 처리하기 위한 딥러닝 알고리즘 중 하나이다. Flatten한 데이터를 처리하는 Fully Connected Neural Network와 다르게 이미지의 공간 정보 데이터를 유지하여 이미지를 인식할 수 있도록 만든다. 이를 위해서 Filter, Pooling, Padding, Stride 등의 개념들이 사용되며, 천천히 알아가보도록 하겠습니다. 출처/참고자료 : http:... Read more 08 Jun 2021 - 25 minute read
Entropy와 Gini계수
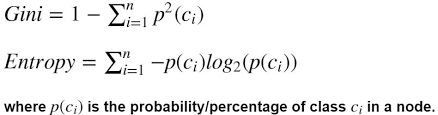
목적 지난번 포스팅에 ensemble 모델에 관하여 이야기하면서 약한 모형으로 의사결정나무를 많이 사용하는 것을 알 수 있었습니다. 이번에는 의사결정 나무를 만들기 위하여 사용되는 Entropy와 gini index에 대해서 알아보도록 하겠습니다. 트리 구축의 원칙 출처 : https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=ehdrndd&logNo=221158124011 결정 트리를 구축할 때는 Occamm의 면도날처럼 데이터의 특성을 가장 잘 반영하는 간단한 가설을 먼저 채택하도록 되어있습니다. ... Read more 01 Jun 2021 - 14 minute read
앙상블(Ensemble) 모델
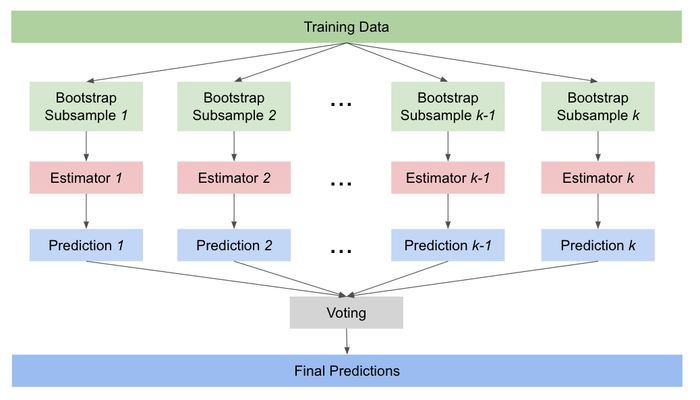
목적 지금까지 랜덤포레스트, xgboost, 딥러닝 등의 모델을 활용하고 비교할 때 단지 rmse 등의 metric을 통한 성능으로 모델을 결정하였다. 이에 대하여 앙상블 모델에 대하여 완벽하진 않지만 개념적으로 이해를 하는 것이 좋다고 판단되었다. 앙상블 모델이란? 하나의 모델을 통한 결과가 아닌 다수의 모델을 활용하여 결과를 향상시키도록 하는 학습 모델 다수의 약한 모형(Weak learner, ex. 의사결정 나무)를 종합하여 강한 모형(String learner)를 만드는 것이 목적이다. 정확도가 높아지면서 해석의 모호함이 생길 수 있습니다. 출처 : http... Read more 28 May 2021 - 4 minute read
GIS 관련 API에 대한 도움글

1. API란? API(Application Programming Interface, 응용 프로그램 프로그래밍 인터페이스) : 응용 프로그램에서 사용할 수 있도록, 운영 체제나 프로그래밍 언어가 제공하는 기능을 제어할 수 있게 만든 인터페이스를 뜻한다. 출처 : 위키피디아 출처 : moonspam님의 gitpage A. Naver MAP API 네이버에서는 Storage, DB, 이미지, 자연어 등 다양한 API 서비스를 제공하고 있습니다. 그 중에서 GIS 관련 서비스를 모아둔 MAPS 의 API에 대해서 살펴보겠습니다. 위의 링크로 가게되면 서비스의 종류와 요금 안내를 받을 수 있습니다.... Read more 24 May 2021 - 24 minute read