Diary of Chanjun 데이터 분석가의 다이어리
시계열 데이터 - ARIMA
학습목적
시계열 데이터를 다루는 법과 시계열 예측을 하기 위한 여러가지 모델을 사용해보고 특성을 이해한다.
이를 위해서 데이콘에서 진행 중인 대회인 전력사용량 예측 AI 경진대회의 데이터를 사용하고, 베이스라인 코드를 따라하고 또 나만의 코드로 만들어 결과를 제출하여 순위도 확인해볼 것이다.
이 장에서는 ARIMA 모형만 다루고 EDA를 다루지 않습니다.
시계열 데이터란?
일정 시간 간격으로 배치된 데이터
시계열 분석의 목표
이런 시계열이 어떤 법칙에서 생성되는지 기본적인 질문을 이해하는 것
시계열 예측
주어진 시계열을 보고 수학적인 모델을 만들어서 미래에 일어날 것들을 예측하는 것 (X가 시계열 Y가 예측값)
일반적으로 이런 방법들은 금융시장에서의 주가 예측 등에서 많이 쓰인다.
출처 : https://ko.wikipedia.org/wiki/%EC%8B%9C%EA%B3%84%EC%97%B4
관련 단어 :
- 계절성 : 특정 주기의 패턴을 가짐
- 주기성 : 특정 패턴을 가지나 일정한 주기를 갖지 않음
- 추세성 : 장기적으로 변화해가는 흐름
- 정상성 : 시계열 데이터가 추세나 계절성을 가지고 있지 않은 평균과 분산이 일정하여 시계열의 특징이 관측된 시간에 무관한 성질(주기성은 가질 수 있음) - 대부분의 시계열 데이터는 비정상성
- 차분 : 평균이 일정하지 않은 시계열에 대하여 평균을 일정하게 만드는 작업
- 일반 차분 : 전 시점의 자료의 차를 구하여 평균을 일정하게 만드는 방법
- 계절 차분 : 계절성이 있는 자료에서 여러 시점의 차를 구하여 평균을 일정하게 만드는 방법
—

- 각 그림의 성질
- 추세성 : a, c, e, f, i
- 계절성 : d, h, i
- 주기성 : g
- 분산의 증가 : i
- 정상성 : b, g
ARIMA(Autoregressvie integrated MovingAverage)
정의 :
- 정상 시계열 데이터의 과거 관측값과 오차를 통하여 현재 시계열값을 예측하는 시계열 분석 기법 중 하나
- AR(Autoregression/자기상관) : 이전의 값이 이후의 값에 영향을 미치고 있는 상황
- AR(1) 모델의 경우: yt = c + φ 1yt-1 + εt (−1 <ϕ1 <1)
- AR(2) 모델의 경우: yt = c + φ 1yt-1 + φ 2yt-2 + εt
- I(Integrate/누적) : 차분을 이용
- MA(Moving Average/이동평균) : 랜덤 변수의 평균값이 지속적으로 증가하거나 감소하는 추세
- ARIMA는 총 세개의 부분으로 이루어져 ARIMA(p, d, q)로 이루어진다.
- 통상적으로 p + q < 2, p * q = 0 조건을 만족하는 모델을 사용한다고 한다.


import os
import sys
import warnings
from tqdm import tqdm
import itertools
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import plotnine as p9
import seaborn as sns
import scipy
import stats
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
from statsmodels.tsa.seasonal import seasonal_decompose
from statsmodels.tsa.stattools import adfuller, kpss
from sklearn.metrics import mean_absolute_error
%matplotlib inline
warnings.filterwarnings("ignore")
mpl.rcParams['axes.unicode_minus'] = False
# fm._rebuild()
plt.rcParams["font.family"] = 'NanumMyeongjo'
plt.rcParams["figure.figsize"] = (10,10)
y = 1
coff = 0.3
const = 0
ar_process = []
for i in range(300):
error = np.random.randn()
y = const + y * coff + error
ar_process.append(y)
print(const / (1 - coff))
plt.plot(ar_process)
0.0
[<matplotlib.lines.Line2D at 0x27c015223a0>]

ma_process = []
error = np.random.randn()
for i in range(300):
ex_error = error
error = np.random.randn()
y = const + coff * ex_error + error
ma_process.append(y)
plt.plot(ma_process)
[<matplotlib.lines.Line2D at 0x27c015709d0>]

train = pd.read_csv("data/dacon/energy/train.csv", encoding = "cp949")
train.head()
| num | date_time | 전력사용량(kWh) | 기온(°C) | 풍속(m/s) | 습도(%) | 강수량(mm) | 일조(hr) | 비전기냉방설비운영 | 태양광보유 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2020-06-01 00 | 8179.056 | 17.6 | 2.5 | 92.0 | 0.8 | 0.0 | 0.0 | 0.0 |
| 1 | 1 | 2020-06-01 01 | 8135.640 | 17.7 | 2.9 | 91.0 | 0.3 | 0.0 | 0.0 | 0.0 |
| 2 | 1 | 2020-06-01 02 | 8107.128 | 17.5 | 3.2 | 91.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 1 | 2020-06-01 03 | 8048.808 | 17.1 | 3.2 | 91.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4 | 1 | 2020-06-01 04 | 8043.624 | 17.0 | 3.3 | 92.0 | 0.0 | 0.0 | 0.0 | 0.0 |
train.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 122400 entries, 0 to 122399
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 num 122400 non-null int64
1 date_time 122400 non-null object
2 전력사용량(kWh) 122400 non-null float64
3 기온(°C) 122400 non-null float64
4 풍속(m/s) 122400 non-null float64
5 습도(%) 122400 non-null float64
6 강수량(mm) 122400 non-null float64
7 일조(hr) 122400 non-null float64
8 비전기냉방설비운영 122400 non-null float64
9 태양광보유 122400 non-null float64
dtypes: float64(8), int64(1), object(1)
memory usage: 9.3+ MB
test = pd.read_csv("data/dacon/energy/test.csv", encoding = "cp949")
test.head()
| num | date_time | 기온(°C) | 풍속(m/s) | 습도(%) | 강수량(mm, 6시간) | 일조(hr, 3시간) | 비전기냉방설비운영 | 태양광보유 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2020-08-25 00 | 27.8 | 1.5 | 74.0 | 0.0 | 0.0 | NaN | NaN |
| 1 | 1 | 2020-08-25 01 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | 1 | 2020-08-25 02 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | 1 | 2020-08-25 03 | 27.3 | 1.1 | 78.0 | NaN | 0.0 | NaN | NaN |
| 4 | 1 | 2020-08-25 04 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
test.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10080 entries, 0 to 10079
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 num 10080 non-null int64
1 date_time 10080 non-null object
2 기온(°C) 3360 non-null float64
3 풍속(m/s) 3360 non-null float64
4 습도(%) 3360 non-null float64
5 강수량(mm, 6시간) 1680 non-null float64
6 일조(hr, 3시간) 3360 non-null float64
7 비전기냉방설비운영 2296 non-null float64
8 태양광보유 1624 non-null float64
dtypes: float64(7), int64(1), object(1)
memory usage: 708.9+ KB
print(train.num.nunique())
print(test.num.nunique())
print(pd.concat([train.num.value_counts().sort_index(), test.num.value_counts()], axis = 1).head())
60
60
num num
1 2040 168
2 2040 168
3 2040 168
4 2040 168
5 2040 168
train.date_time = pd.to_datetime(train.date_time)
test.date_time = pd.to_datetime(test.date_time)
train.date_time.describe()
count 122400
unique 2040
top 2020-08-13 07:00:00
freq 60
first 2020-06-01 00:00:00
last 2020-08-24 23:00:00
Name: date_time, dtype: object
test.date_time.describe()
count 10080
unique 168
top 2020-08-28 18:00:00
freq 60
first 2020-08-25 00:00:00
last 2020-08-31 23:00:00
Name: date_time, dtype: object
print(2040 * 60)
print(168 * 60)
122400
10080
train.iloc[:,2:].head()
| 전력사용량(kWh) | 기온(°C) | 풍속(m/s) | 습도(%) | 강수량(mm) | 일조(hr) | 비전기냉방설비운영 | 태양광보유 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 8179.056 | 17.6 | 2.5 | 92.0 | 0.8 | 0.0 | 0.0 | 0.0 |
| 1 | 8135.640 | 17.7 | 2.9 | 91.0 | 0.3 | 0.0 | 0.0 | 0.0 |
| 2 | 8107.128 | 17.5 | 3.2 | 91.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 8048.808 | 17.1 | 3.2 | 91.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4 | 8043.624 | 17.0 | 3.3 | 92.0 | 0.0 | 0.0 | 0.0 | 0.0 |
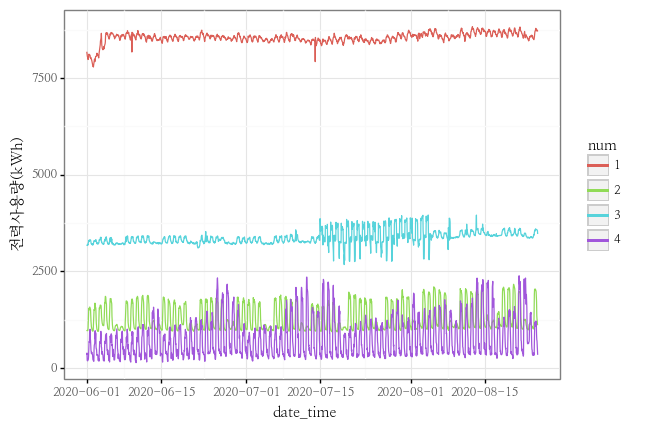
y_col = "전력사용량(kWh)"
idxs = [1, 2, 3, 4]
(
p9.ggplot() +
p9.geom_line(data = train[train.num.isin(idxs)].assign(num = lambda x : x.num.astype(str)), mapping = p9.aes(x = "date_time", y = y_col, color = "num", group = "num")) +
p9.theme_bw() +
p9.theme(text = p9.element_text(family = "NanumMyeongjo"))
)

<ggplot: (170728743361)>
시계열분해
- 시계열 요소 데이터를 추세-주기, 계절성, 나머지(Error) 세가지로 나누어 보여주는 방식
시계열분해
- ARIMA 예측을 위해서는 정상성을 만족해야합니다. 이를 위해 정상성 테스트를 하는 두가지 방법을 소개하겠습니다.
| TEST NAME | 판단 요소 | 판단 기준 |
|---|---|---|
| adf | Trend | 추세가 제거되면 정상이라고 판단 |
| kpss | Seosonality | 계절성이 제거되면 정상이라고 판단 |
출처 : https://skyeong.net/285
출처 : https://sosoeasy.tistory.com/392
def print_adfuller(inputSeries):
result = adfuller(inputSeries)
print('ADF Statistic: %f' % result[0])
print('p-value: %f' % result[1])
def print_kpss(inputSeries):
result = kpss(inputSeries)
print('KPSS Statistic: %f' % result[0])
print('p-value: %f' % result[1])
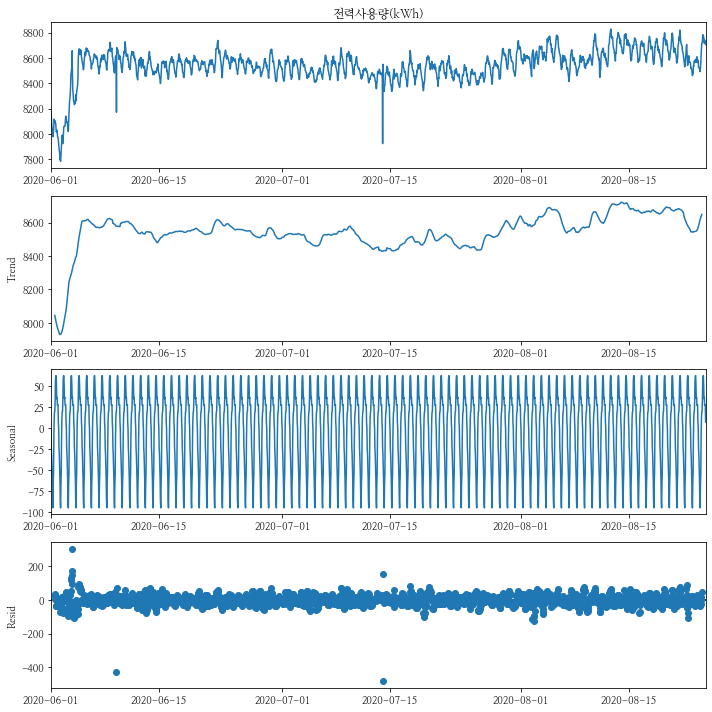
num이 1번인 건물의 시계열분해를 해보도록 하겠습니다.
-
Trend는 거의 보이지 않으나, Seosonality는 확연하게 보이는 것으로 보입니다.
- 시간에 대해서 반복(하루 주기)을 하는 것을 확인할 수 있습니다.
- 트렌드에 대한 테스트인 ADF의 경우 p-value가 0으로 정상성을 띄고 있습니다.
- 계절성에 대한 테스트인 KPSS의 경우 p-value가 0.01로 0.05보다 작아 정상성을 띄지 않습니다.
decompose_df = train[train.num == 1][["date_time", y_col]].set_index("date_time")
decompse_result = seasonal_decompose(decompose_df[y_col])
decompse_result.plot()
plt.show()

print_adfuller(decompose_df)
ADF Statistic: -5.900664
p-value: 0.000000
print_kpss(decompose_df)
KPSS Statistic: 1.791702
p-value: 0.010000
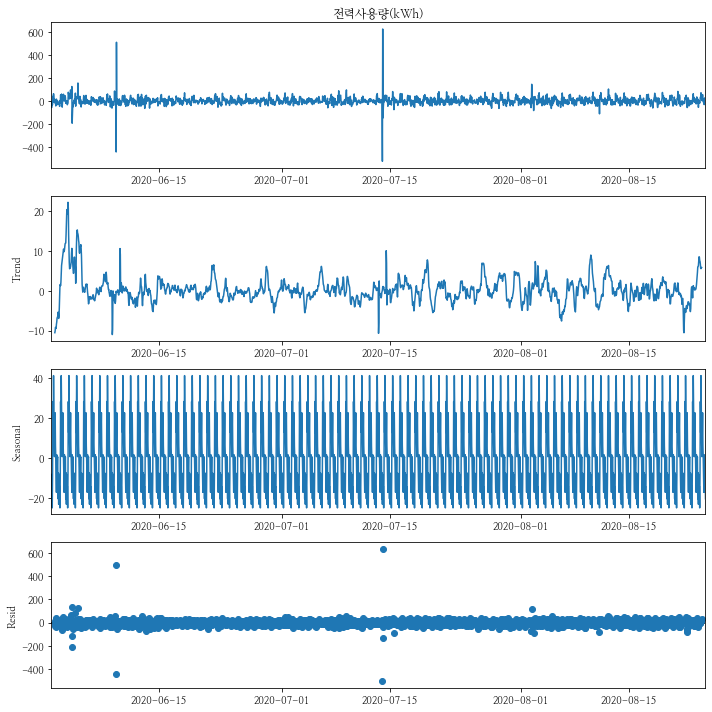
num이 1번인 건물의 차분을 1로 하여 시계열분해를 해보도록 하겠습니다.
- Trend는 거의 보이지 않으나, Seosonality는 역시 확연하게 보이는 것으로 보입니다.
- 시간에 대해서 반복(하루 주기)을 하는 것을 확인할 수 있습니다.
- 트렌드에 대한 테스트인 ADF의 경우 p-value가 0으로 정상성을 띄고 있습니다.
- 하지만 계절성에 대한 테스트인 KPSS의 경우 p-value가 0.1로 0.05보다 정상성을 띄고 있습니다.
decompose_df_d1 = decompose_df - decompose_df.shift(1)
decompse_result_d1 = seasonal_decompose(decompose_df_d1[y_col][1:])
decompse_result_d1.plot()
plt.show()

seosonality_chk = decompse_result_d1.seasonal.reset_index().assign(day = lambda x : x.date_time.dt.day, hour = lambda x : x.date_time.dt.hour).groupby(by = "seasonal").hour.unique()
seosonality_chk = seosonality_chk.reset_index()
seosonality_chk.iloc[seosonality_chk.apply(lambda x : x.hour[0], axis = 1).sort_values().index]
| seasonal | hour | |
|---|---|---|
| 10 | -7.484606 | [0] |
| 1 | -23.279445 | [1] |
| 9 | -8.214249 | [2] |
| 4 | -15.593606 | [3] |
| 5 | -14.263374 | [4] |
| 0 | -25.089410 | [5] |
| 8 | -8.289303 | [6] |
| 22 | 28.361108 | [7] |
| 18 | 12.748197 | [8] |
| 23 | 41.420590 | [9] |
| 21 | 22.865965 | [10] |
| 17 | 8.701412 | [11] |
| 14 | 0.666853 | [12] |
| 19 | 13.516894 | [13] |
| 20 | 22.731447 | [14] |
| 16 | 6.116965 | [15] |
| 12 | 0.333501 | [16] |
| 6 | -10.214499 | [17] |
| 3 | -17.286678 | [18] |
| 15 | 1.598751 | [19] |
| 7 | -9.401928 | [20] |
| 11 | -0.015088 | [21] |
| 13 | 0.566055 | [22] |
| 2 | -20.495553 | [23] |
print_adfuller(decompose_df_d1[1:])
ADF Statistic: -8.993809
p-value: 0.000000
print_kpss(decompose_df_d1[1:])
KPSS Statistic: 0.048369
p-value: 0.100000
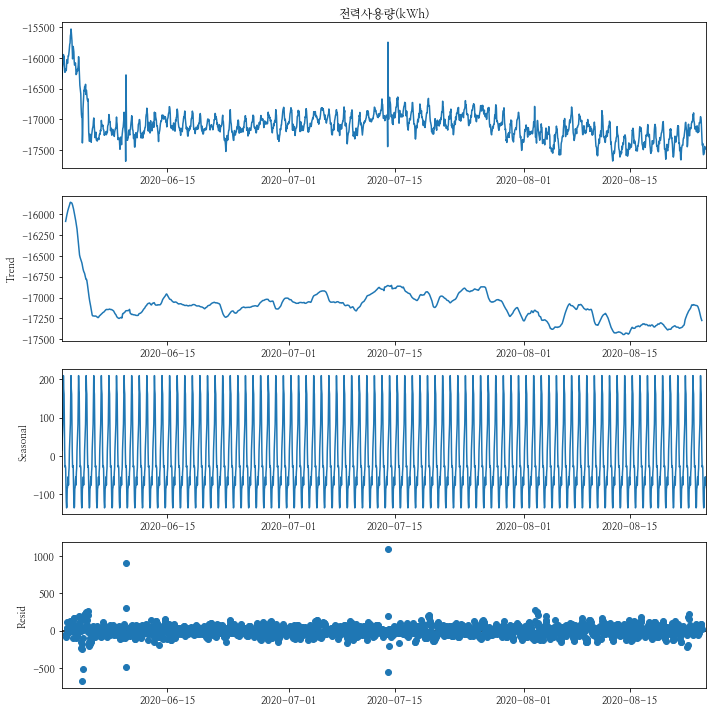
num이 1번인 건물의 차분을 2로 하여 시계열분해를 해보도록 하겠습니다.
-
역시 Trend는 거의 보이지 않으나, Seosonality는 역시 확연하게 보이는 것으로 보입니다.
- 시간에 대해서 반복(하루 주기)을 하는 것을 확인할 수 있습니다.
- 트렌드에 대한 테스트인 ADF의 경우 p-value가 0으로 정상성을 띄고 있습니다.
- 계절성에 대한 테스트인 KPSS의 경우 p-value가 0.01로 0.05보다 작아 정상성을 띄지 않습니다.
decompose_df_d2 = decompose_df - (2*decompose_df.shift(1)) + decompose_df.shift(2)
decompse_result_d2 = seasonal_decompose(decompose_df_d2[y_col][2:])
decompse_result_d2.plot()
plt.show()

seosonality_chk = decompse_result_d2.seasonal.reset_index().assign(day = lambda x : x.date_time.dt.day, hour = lambda x : x.date_time.dt.hour).groupby(by = "seasonal").hour.unique()
seosonality_chk = seosonality_chk.reset_index()
seosonality_chk.iloc[seosonality_chk.apply(lambda x : x.hour[0], axis = 1).sort_values().index]
| seasonal | hour | |
|---|---|---|
| 18 | 13.001128 | [0] |
| 3 | -15.804657 | [1] |
| 19 | 15.055378 | [2] |
| 10 | -7.389175 | [3] |
| 14 | 1.320414 | [4] |
| 7 | -10.835854 | [5] |
| 20 | 16.790289 | [6] |
| 23 | 36.640593 | [7] |
| 4 | -15.622729 | [8] |
| 22 | 28.662575 | [9] |
| 1 | -18.564443 | [10] |
| 5 | -14.174372 | [11] |
| 9 | -7.681234 | [12] |
| 17 | 12.712712 | [13] |
| 15 | 9.204736 | [14] |
| 2 | -16.624300 | [15] |
| 12 | -5.793282 | [16] |
| 8 | -10.557818 | [17] |
| 11 | -7.081997 | [18] |
| 21 | 18.875611 | [19] |
| 6 | -11.010497 | [20] |
| 16 | 9.377021 | [21] |
| 13 | 0.571325 | [22] |
| 0 | -21.071425 | [23] |
print_adfuller(decompose_df_d2[2:])
ADF Statistic: -25.306054
p-value: 0.000000
print_kpss(decompose_df_d2[2:])
KPSS Statistic: 0.012631
p-value: 0.100000
AR, MA의 모수 추정
- ACF(Autocorrelation function) : Lag에 따른 관측치들 사이의 관련성을 측정하는 함수
- PACF(Partial autocorrelation function) : k 이외의 모든 다른 시점 관측치의 영향력을 배제하고 yt와 yt-k 두 관측치의 관련성을 측정하는 함수

- 사실 위에 정의를 정확히 이해하진 못하였으니 일단 이것만 기억하도록 한다.
출처 : https://tjansry354.tistory.com/14
출처 : https://kerpect.tistory.com/161
출처 : https://byeongkijeong.github.io/ARIMA-with-Python/
plt.rcParams["figure.figsize"] = (5, 3)
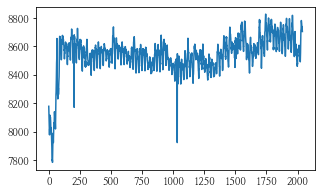
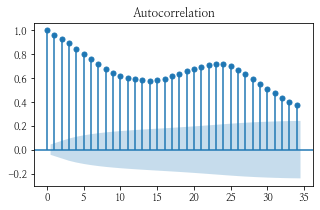
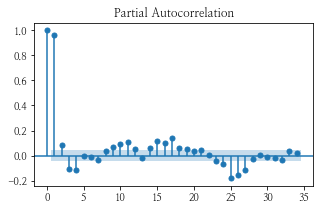
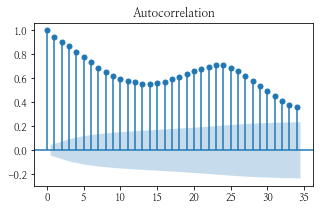
num이 1인 데이터의 plot과 acf, pacf 그래프를 그려보았다.
- 그림 상 보았을 때, acf 그래프가 사인 함수처럼 보이고 pacf가 1에서 급격히 떨어지는 것을 보아 아마 p = 1 이 적당하지 않을까 싶다.
idx = 1
series = train[train.num == idx][y_col]
series.plot()
plot_acf(series)
plot_pacf(series)
plt.show()



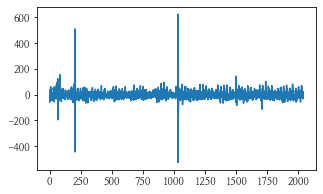
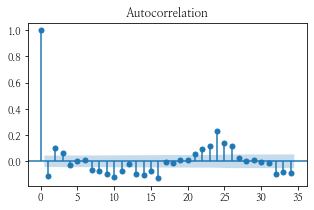
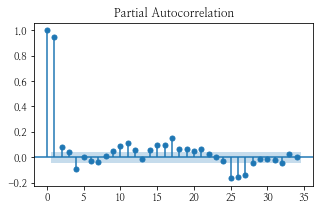
차분을 1차 하여 num이 1인 데이터의 plot과 acf, pacf 그래프를 그려보았다.
- plot이 중심점에서 노이즈만 있는 것처럼 바뀌었고, acf, pacf 둘 다 0에서 급격히 떨어지것을 보아 p-q = 0이고 d = 1인 (1, 1, 1) 혹은 (2, 1, 2)가 적당하지 않을까 예상해본다.
series_d1 = series - series.shift(1)
series_d1.plot()
plot_acf(series_d1[1:])
plot_pacf(series_d1[1:])
plt.show()



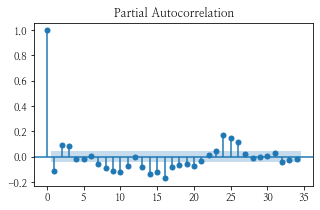
차분을 2차 하여 num이 1인 데이터의 plot과 acf, pacf 그래프를 그려보았다.
- plot은 차분을 안 한 데이터가 반전된 것처럼 보이고, acf, pacf는 거의 비슷하다.
series_d2 = series - (2*series.shift(1)) + series.shift(2)
series_d2.plot()
plot_acf(series_d2[2:])
plot_pacf(series_d2[2:])
plt.show()



cut = int(len(series) * 0.8)
train = series[:cut]
val = series[cut:]
pdq_list = list(itertools.product(range(3), range(3), range(3)))
pd_lists = list()
for pdq in tqdm(pdq_list[1:]) :
arima = ARIMA(train, order = pdq)
arima = arima.fit()
predict = arima.predict(start = 1, end = len(val))
aicc = arima.aicc
aic = arima.aic
bic = arima.bic
mae = mean_absolute_error(val, predict)
pd_lists = pd_lists + [[pdq, aicc, aic, bic, mae]]
100%|███████████████████████████████████████████████████| 26/26 [00:08<00:00, 3.11it/s]
arima_metric = pd.DataFrame(pd_lists, columns = ["pdq", "aicc", "aic", "bic", "mae"])
arima_metric.head()
| pdq | aicc | aic | bic | mae | |
|---|---|---|---|---|---|
| 0 | (0, 0, 1) | 18897.962018 | 18897.947276 | 18914.139960 | 149.379200 |
| 1 | (0, 0, 2) | 18062.369967 | 18062.345382 | 18083.935628 | 156.448449 |
| 2 | (0, 1, 0) | 16422.809294 | 16422.806839 | 16428.203787 | 173.148794 |
| 3 | (0, 1, 1) | 16382.330861 | 16382.323490 | 16393.117387 | 173.129768 |
| 4 | (0, 1, 2) | 16364.348722 | 16364.333971 | 16380.524817 | 173.133983 |
- AICc, AIC, BIC는 모두 똑같은 상관관계를 갖게 되지만, 평가 metric인 mae와는 음의 상관관계를 보이고 있습니다.
sns.heatmap(arima_metric.iloc[:, 1:].corr(), annot = True, fmt = ".2f", cmap = "Blues")
<AxesSubplot:>

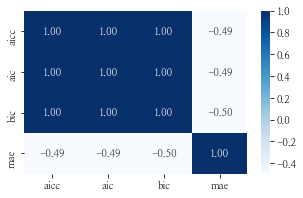
- aicc, aic, bic가 최소/최대가 되는 pdq의 조합은 동일하였습니다.
- 그러나 우리가 평가받아야될 mae는 최소/최대 조합이 달랐습니다.
print(arima_metric[arima_metric["aicc"] == arima_metric["aicc"].max()])
print(arima_metric[arima_metric["aㅅicc"] == arima_metric["aicc"].min()])
pdq aicc aic bic mae
0 (0, 0, 1) 18897.962018 18897.947276 18914.13996 149.3792
pdq aicc aic bic mae
19 (2, 0, 2) 16344.79814 16344.746448 16377.131817 170.946399
print(arima_metric[arima_metric["aic"] == arima_metric["aic"].max()])
print(arima_metric[arima_metric["aic"] == arima_metric["aic"].min()])
pdq aicc aic bic mae
0 (0, 0, 1) 18897.962018 18897.947276 18914.13996 149.3792
pdq aicc aic bic mae
19 (2, 0, 2) 16344.79814 16344.746448 16377.131817 170.946399
print(arima_metric[arima_metric["bic"] == arima_metric["bic"].max()])
print(arima_metric[arima_metric["bic"] == arima_metric["bic"].min()])
pdq aicc aic bic mae
0 (0, 0, 1) 18897.962018 18897.947276 18914.13996 149.3792
pdq aicc aic bic mae
19 (2, 0, 2) 16344.79814 16344.746448 16377.131817 170.946399
print(arima_metric[arima_metric["mae"] == arima_metric["mae"].max()])
print(arima_metric[arima_metric["mae"] == arima_metric["mae"].min()])
pdq aicc aic bic mae
5 (0, 2, 0) 17802.388635 17802.386178 17807.782513 187.044582
pdq aicc aic bic mae
0 (0, 0, 1) 18897.962018 18897.947276 18914.13996 149.3792
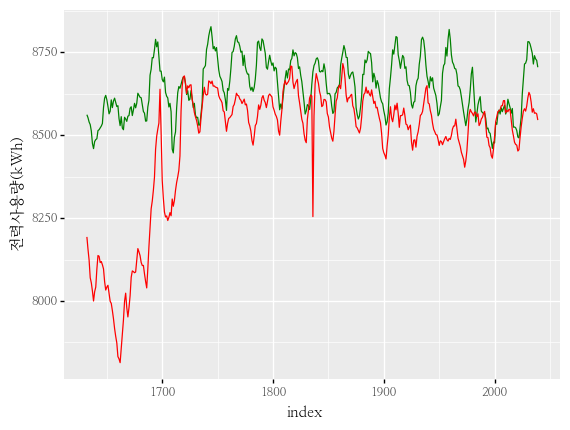
- aicc, aic, bic가 최소값을 갖는 조합의 그래프입니다.
arima = ARIMA(train, order = (2, 0, 2))
arima = arima.fit()
predict = arima.predict(start = 1, end = len(val))
predict.index = val.index
(
p9.ggplot() +
p9.geom_line(data = val.reset_index(), mapping = p9.aes(x = "index", y = y_col), group = 1, color = "green") +
p9.geom_line(data = predict.reset_index(), mapping = p9.aes(x = "index", y = "predicted_mean"), group = 1, color = "red") +
p9.theme(text = p9.element_text(family = "NanumMyeongjo"))
)

<ggplot: (170731823863)>
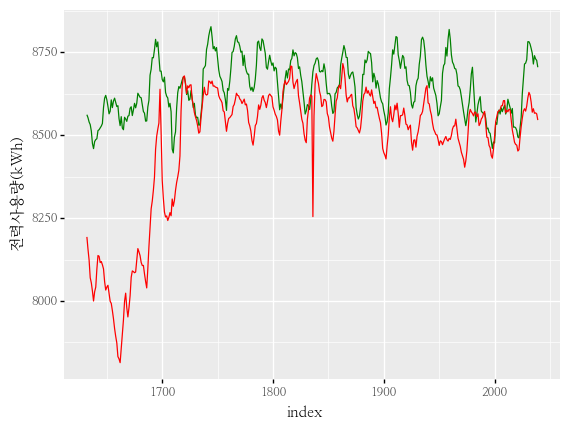
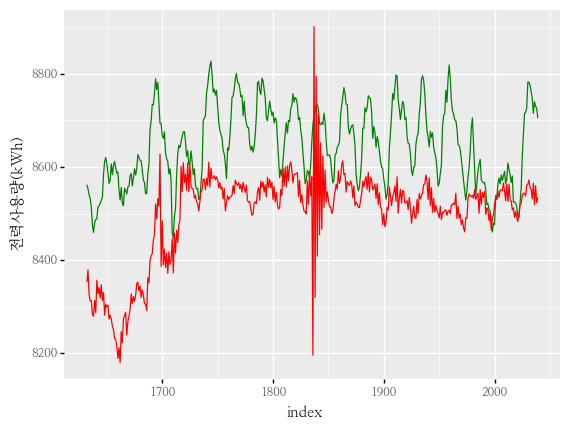
- aicc, aic, bic가 최대값 / mae가 최소값을 갖는 조합의 그래프입니다.
arima = ARIMA(train, order = (0, 0, 1))
arima = arima.fit()
predict = arima.predict(start = 1, end = len(val))
predict.index = val.index
(
p9.ggplot() +
p9.geom_line(data = val.reset_index(), mapping = p9.aes(x = "index", y = y_col), group = 1, color = "green") +
p9.geom_line(data = predict.reset_index(), mapping = p9.aes(x = "index", y = "predicted_mean"), group = 1, color = "red") +
p9.theme(text = p9.element_text(family = "NanumMyeongjo"))
)

<ggplot: (170730380746)>
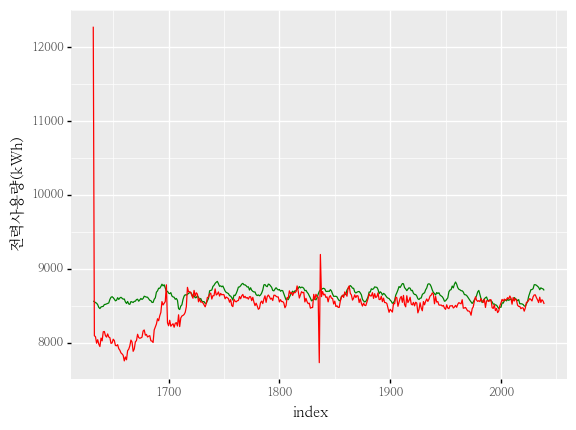
- mae가 최대값을 갖는 조합의 그래프입니다.
arima = ARIMA(train, order = (0, 2, 0))
arima = arima.fit()
predict = arima.predict(start = 1, end = len(val))
predict.index = val.index
(
p9.ggplot() +
p9.geom_line(data = val.reset_index(), mapping = p9.aes(x = "index", y = y_col), group = 1, color = "green") +
p9.geom_line(data = predict.reset_index(), mapping = p9.aes(x = "index", y = "predicted_mean"), group = 1, color = "red") +
p9.theme(text = p9.element_text(family = "NanumMyeongjo"))
)

<ggplot: (170728889266)>
- ARIMA의 모델 성능 지표인 AIC와 우리가 최소화시켜야할 MAE가 최소가 되는 점이 다르다는 것과 정상성 test나 acf, pacf의 그래프에서 봤던 예상했던 결과와 전혀 다른 결과가 나왔습니다.
- 좀 더 공부가 부족하여 이런 결과가 나온것은 아닐 지 더 공부를 해보아야겠습니다.
- 대회가 아닌 실무에서는 무조건 mae가 낮다고 좋은 모델이 아닐 수 있다는 점을 유의하며 모델링을 해나가야겠습니다.
code : https://github.com/Chanjun-kim/Chanjun-kim.github.io/blob/main/_posts/2021-06-08-TimeSeries1.md
참고 자료 :
- https://dacon.io/competitions/official/235736/codeshare/2628?page=1&dtype=recent
- https://byeongkijeong.github.io/ARIMA-with-Python/
- https://otexts.com/fppkr/arima-estimation.html
- https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=gandharva3&logNo=40004397630