Diary of Chanjun 데이터 분석가의 다이어리
앙상블(Ensemble) 모델
목적
- 지금까지 랜덤포레스트, xgboost, 딥러닝 등의 모델을 활용하고 비교할 때 단지 rmse 등의 metric을 통한 성능으로 모델을 결정하였다. 이에 대하여 앙상블 모델에 대하여 완벽하진 않지만 개념적으로 이해를 하는 것이 좋다고 판단되었다.
앙상블 모델이란?
하나의 모델을 통한 결과가 아닌 다수의 모델을 활용하여 결과를 향상시키도록 하는 학습 모델
- 다수의 약한 모형(Weak learner, ex. 의사결정 나무)를 종합하여 강한 모형(String learner)를 만드는 것이 목적이다.
- 정확도가 높아지면서 해석의 모호함이 생길 수 있습니다.
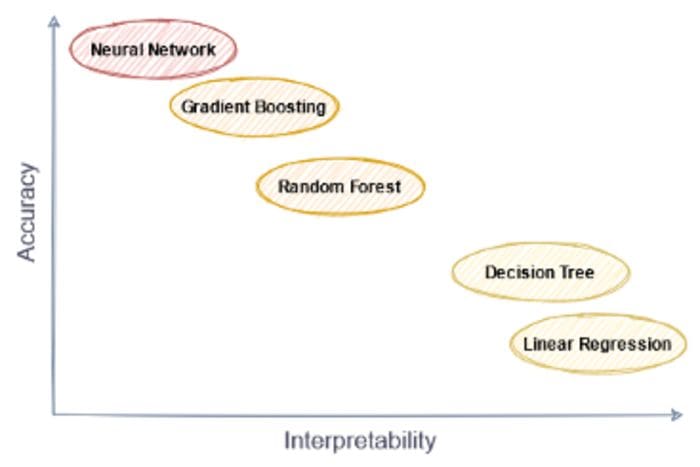
출처 : https://www.kdnuggets.com/2021/05/explainable-boosting-machine.html
위의 그림과 같이 앙상블 모델의 종류인 Gradient Boosting과 Random Forest는 Decision Tree, 선형회귀보다는 높은 정확도를 가지나, 해석력에 있어서 불리하다는 단점을 가지고 있습니다.
앙상블 모델의 종류
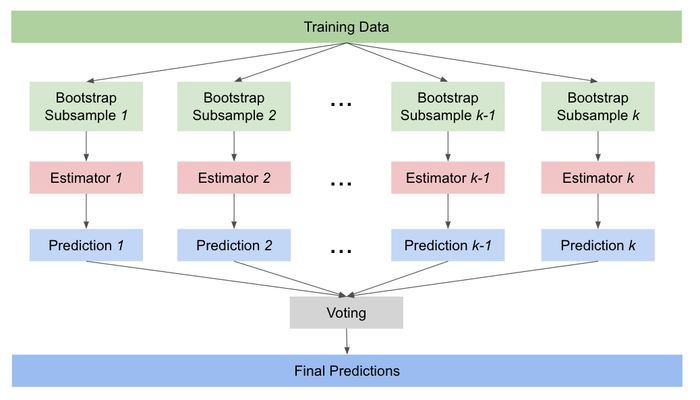
- Voting : 여러개의 모델의 결과를 토대로 다수의 분류기가 예측한 값 혹은 평균 등을 최종 결과로 선정하는 앙상블 모형
- Bagging : Bootstrap Aggregation의 약자로, 동일한 알고리즘으로 여러개의 약한 모형를 Boot Strapping된 샘플 데이터를 학습시켜 예측하는 앙상블 모형 (참고)
- Boosting : 약한 모형을 학습시킨 결과에 잔차를 업데이트하며 학습시키는 앙상블 모형
- Stacking : 여러개의 모형의 결과를 다시 학습시켜 최종 결과를 만드는 앙상블 모형
1. Voting
여러개의 모델의 결과를 토대로 다수의 분류기가 예측한 값 혹은 평균 등을 최종 결과로 선정하는 앙상블 모형(참고)
- Hard Voting
- 각 분류기의 결과를 바탕으로 다수의 결과를 최종 결과로 나타냄.
- Soft Voting
- 각 분류기의 결과의 확률을 평균으로하여 최종 결과로 나타냄(일반적으로 사용됨.)
- Regression 모델의 경우 자동으로 평균을 나타냄.(잘 사용하지 않음)

출처 : https://libertegrace.tistory.com/entry/Classification-2-%EC%95%99%EC%83%81%EB%B8%94-%ED%95%99%EC%8A%B5Ensemble-Learning-Voting%EA%B3%BC-Bagging
Voting 방법은 결국 개별 분류기 중 가장 뛰어난 것을 넘기 힘들 것 같지만, 의외로 정확도가 높은 경우가 많다고 합니다.(핸즈온 머신러닝 중)- 또한 앙상블 모형은 모델이 서로 가능한한 독립적일 때 서로 다른 오차를 만들어 최고의 성능을 발휘한다고 합니다.(핸즈온 머신러닝 중)
2. Bagging
Bootstrap Aggregation의 약자로, 동일한 알고리즘으로 여러개의 약한 모형를 Bootstrapping으로 샘플링된 데이터를 학습시켜 예측하는 앙상블 모형
-
약한 모형이란?
- 랜덤 추출보다 예측력이 좋으나 연산이 빠른 모델(ex. Decision Tree)
-
Bootstrap이란?
- 복원 추출이 가능한 Random Sampling 기법
- 복원 추출이 가능하기 때문에 아래의 그림과 같이 각 샘플에서 표본보다 많은 Y값(색깔공)이 보일 수 있습니다.

출처 : https://en.wikipedia.org/wiki/Bootstrap_aggregating
-
Bagging의 장점
- 이렇게 복원 추출을 하면서 본래의 분포와 다른 결과에 대하여 약한 모형이 학습을 하기 때문에 과적합에 강하게 됩니다.
-
분산과 편향
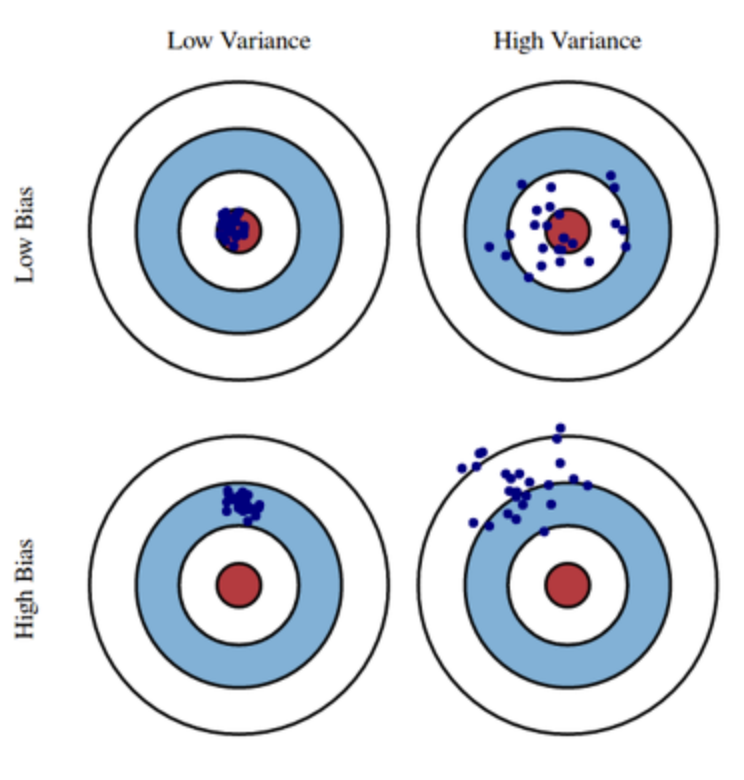
-
출처 : http://bongholee.com/2020/09/%ED%8E%B8%ED%96%A5%EA%B3%BC-%EB%B6%84%EC%82%B0-%EA%B4%80%EC%A0%90%EC%97%90%EC%84%9C-%EB%B0%B0%EA%B9%85bagging%EA%B3%BC-%EB%B6%80%EC%8A%A4%ED%8C%85boosting%EC%9D%98-%EB%B9%84%EA%B5%90/
-
- 트리 모델이 깊어질수록 늘어나는 분산에 대하여 줄일 수 있습니다.
-
tree의 편향과 분산에 대하여
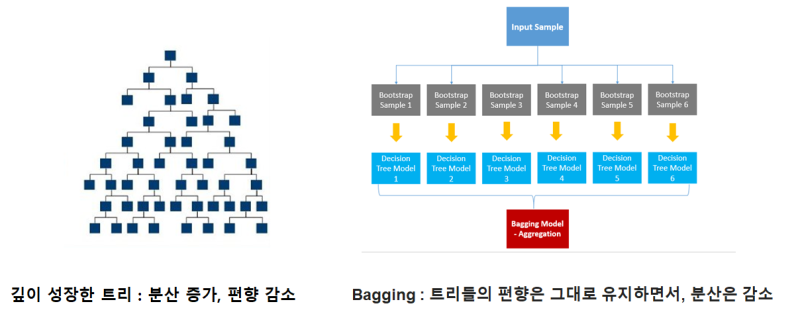
-
출처 : https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=ysd2876&logNo=221219689884
-
- 데이터 상에 있는 노이즈에 대해서 강인해질 수 있습니다.
-
OOB(Out of Bagging)
- BootStrap을 활용하여 샘플링하게 되면 모든 데이터가 활용되지 않을 수 있다. 이를 OOB 데이터라 부르고, 예측 성능을 평가합니다. 이를 통하여 Validation set을 따로 만들지 않아도 됩니다.(약 1/3 정도)
- Cross Validation 의 경우 약 3-fold CV와 비슷한 성능을 가질 것으로 예상.
-
Random Forest
- 의사결정 나무를 모아 숲을 만든다는 개념의 Bagging의 대표적인 모델
- sklearn의 random forest는 최종 aggregation에서 soft voting을 쓴다고 나와있습니다.
-
출처 : https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html
3. Boosting
Boosting은 현재 Kaggle 같은 Competition에서 우수한 성능을 보이는 모델입니다.
Bagging이 병렬적으로 각각 샘플을 학습시키는 반면에,
Boosting은 순차적으로 오분류된 데이터에 가중치를 높여 약한 모형을 학습시켜 강한 모형을 만듭니다.
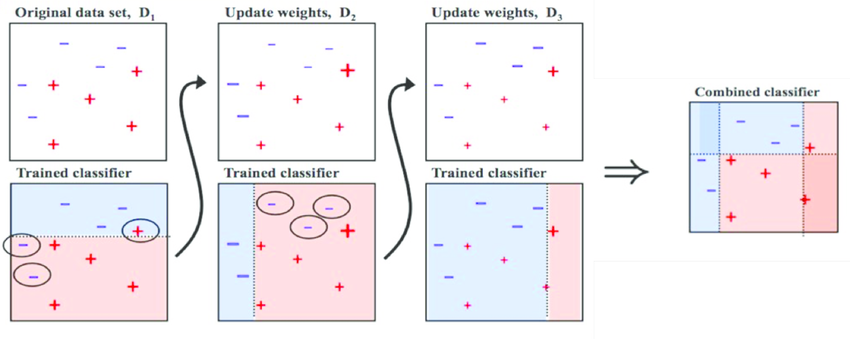
Bagging과 Boosting의 차이

- Bagging 방식에 비하여 과적합이 될 수 있는 위험성을 가졌으나 대체적으로 boosting 계열 모델이 성능이 더 좋게 나온다고 합니다.
대표 모델
- Ada Boosting
-
Adaptive Boosting의 약자로, 오분류된 데이터에 가중치를 주어 학습시킨 모델별로 가중치를 계산하여 최종 분류 모형을 만들어냅니다.
-
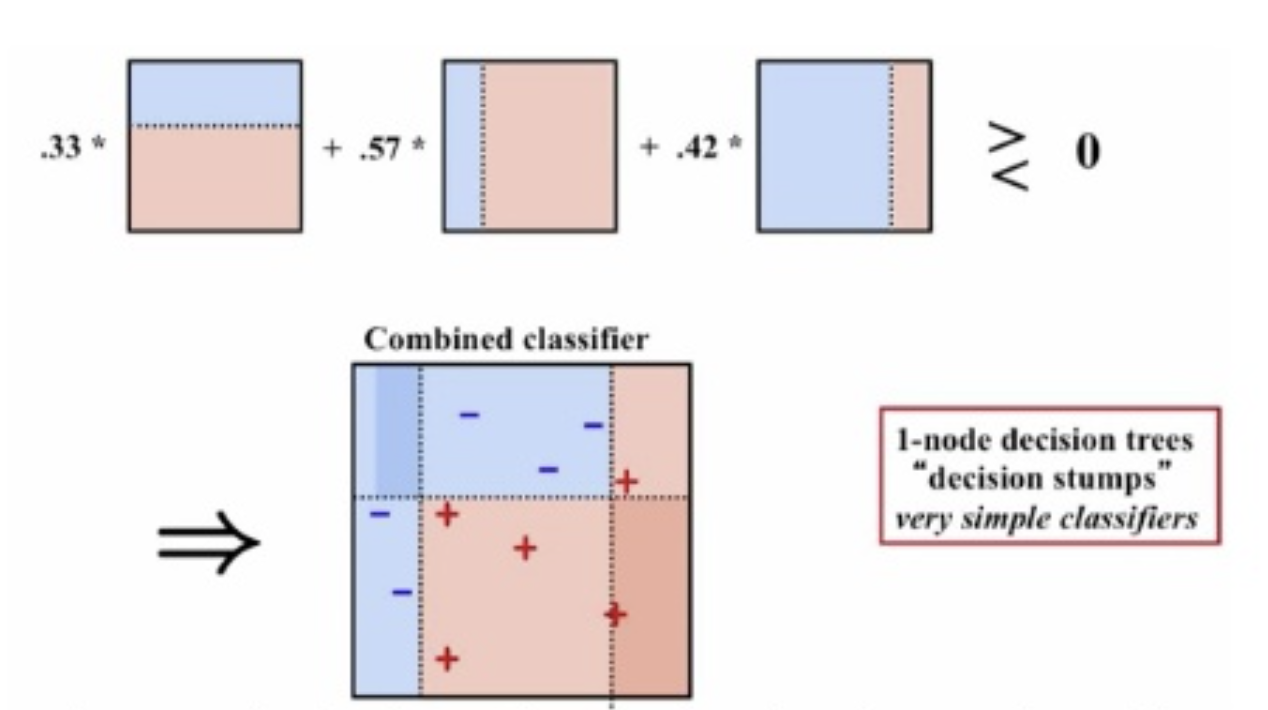
-
Gradient Boosting
- Boosting 방식에 loss function으로 Gradient Descent(경사하강법)을 활용하여 이전 약한 모형의 잔차를 학습하여 보완하는 모델
- 평균에 대한 오차를 구한다.

- Learning rate에 오차만큼을 update하여 오차를 줄인다.

- 이 작업을 반복하여 최종 구조를 만든다.

참고 : https://dailyheumsi.tistory.com/116
추가 자료 : Gradient Boost Visualization
- 특징 : 부스팅 모델에 비하여 과적합에 강인하고 정확도가 높으나, 수행시간이 오래걸림.
- 평균에 대한 오차를 구한다.
대표 모델
- XGboost
- LASSO(L1) 및 Ridge(L2) 정규화(Regulizationi)를 통하여 과적합에 강하다.
- object function, metric 등 다양하게 custom이 가능하다.
그만큼 신경써야될 하이퍼 파라미터가 많다는 의미일 수도.. - 병렬처리로 GBM에 비해서 빠르다.
소개하는 GBM 모델 중엔 가장 느린 것으로 알고 있습니다. - level-wise(bfs) 방식으로 트리를 구성한다.
- Lightgbm
- XGBoost에 비해 적은 자원으로 빠른 연산이 가능
- 연산이 빠르고 성능이 좋으나, 데이터가 부족할 시 과적합이 생길 수 있음.
- XGBoost와 다르게 leaf-wise(dfs) 방식으로 구현
- Catboost
- 앞의 cat이 Category를 의미하며 dummy 변수들이 많을 때 유용하다.
- catgory데이터를 모델링하기 위해서는 one-hot encoding을 활용해야하는데, catboost는 이를 수치형으로 바꾸어 계산하도록 되어있어 편리하고 자원에 대한 부담이 줄어든다.
- 또한 변수 중에 information gain이 동인하면 하나의 feature로 자동으로 묶어준다.
- 최신 모델답게 최적화가 잘 되어있어 하이퍼파라미터 튜닝에 크게 신경쓰지 않아도 된다.
- XGBoost와 같이 level-wise로 트리를 구성
- 앞의 cat이 Category를 의미하며 dummy 변수들이 많을 때 유용하다.
4. Stacking
여러 모델을 사용하는 것에 대해서 Voting과 비슷해보이지만, 각 base model의 결과를 한번 더 학습시켜 최종 결과를 내는 Ensemble model
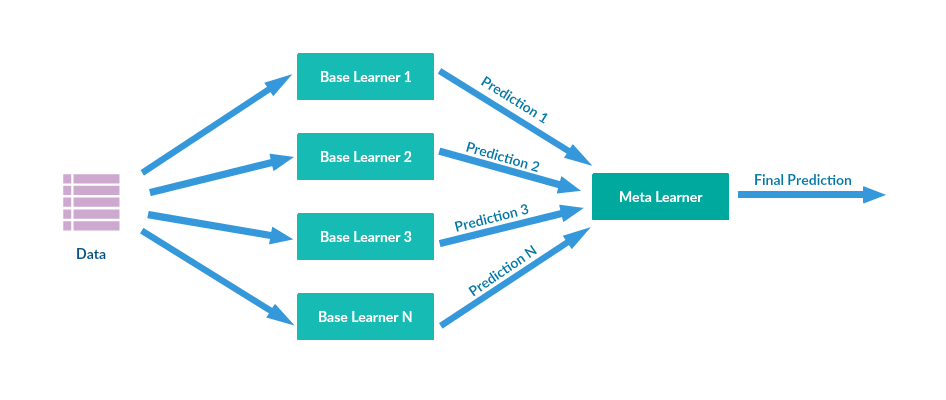
Stacking의 장단점
- 단일 모델보다 높은 성능을 가진다.
- 해석이 애매하고, 과적합될 확률이 높기 때문에 실제 서비스 모델로 구현하기는 어렵다.(캐글 같은 정확도만을 목적으로 하는 대회에서는 많이 사용되는 기법이라고 합니다.)
- 다수의 모델이 필요하므로 학습 속도도 그만큼 오래걸릴 것이다.
참고 자료 : https://bkshin.tistory.com/entry/
https://3months.tistory.com/368
https://dailyheumsi.tistory.com/116
StatQuest with Josh Starmer 의 StatQuest: Gradient Boost Part1 영상
Written on May 28th, 2021 by Chanjun Kim